■ 『nankanOdds』の使い方
使い方といって機能は一つ。南関競馬の単複オッズをクリック一つで取得するというものです。
まずは、起動画面。

ここで「スタート」ボタンをクリックします。
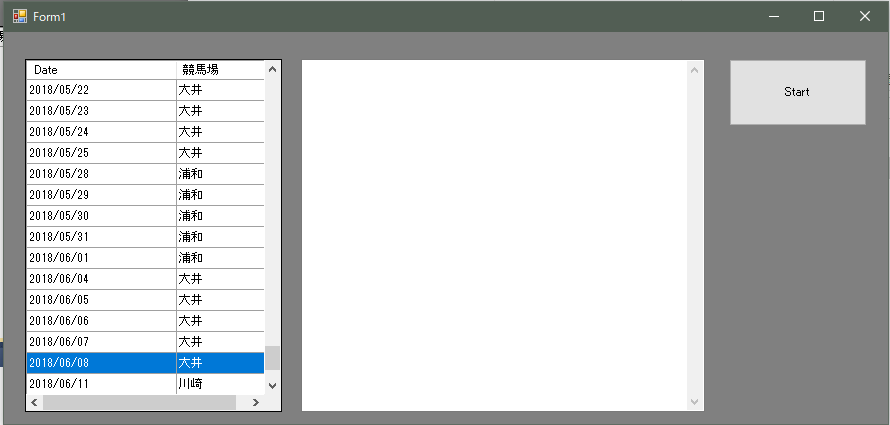
直近(約半年くらい)の南関開催日の一覧が表示されますので、オッズを取得する開催日を選択します。

数秒で全レースのオッズを取得して、ファイルに保存とテキストボックスに取得したオッズを表示します。
たったこれだけですが、オッズを必要とする予想には活用出来るかと思います。
開催日であれば、オッズを時系列で取得することも可能です。
■ プログラミングについて
プログラミングはVisualBasicで行っています。
Nankankeiba.com のオッズ画面のソースをダウンロードして、ソースの中からオッズ等を抜き出すというプロセスで行っています。
■ 開催コード
その、オッズ画面ですが、
https://www.nankankeiba.com/odds/YYYYMMDDPPKKNNRR01.do
がオッズページのURLになります。
アフファベットの意味は以下
YYYY :西暦
MM :月
DD :日
PP :競馬場コード(18:浦和 19:船橋 20:大井 21:川崎)
KK :開催回
NN :開催日
RR :レースNo
となっています。
例えば 2018年6月11日 3回川崎競馬1日目 1レースの単勝 複勝 枠複 枠単 のURLは
https://www.nankankeiba.com/odds/201806112103010101.do
となります。
最後の「01」は区分で、それぞれ
01:単勝 複勝 枠複 枠単
04:馬複 ワイド
03:馬単
09:三連複
08:三連単
の画面となります。
■VisualBasicのコード
それを踏まえたうえで、
Rf= https://www.nankankeiba.com/odds/201806112103010101.do
Wf=出力ファイル名
My.Computer.Network.DownloadFile(Rf, Wf, "", "", True, 60000, True, FileIO.UICancelOption.DoNothing)
としてHTMLソースをダウンロードします。
ダウンロードしたファイルを1行づつ読み込んで、単複オッズのテーブル部分だけを抜き出します。
ソースで見るとH3タグのついた 単勝・複勝 とあるところの下の テーブルタグから
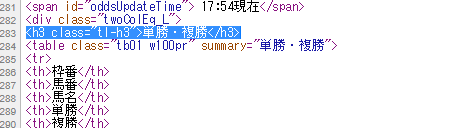
次のテーブルタグの閉じるところまで。

抜き出した単複オッズのテーブル部分のソースを1行ずつ読みこんで、タグだけを取り除きます。
patternStr="<.*?>"
line:読み込んだソース(1行)
として
NL = Regex.Replace(line, patternStr, String.Empty)
といった関数でタグを取り除くと
5
5
サンナイト
10.4
1.5-2.2
6
6
オクシー
28.7
2.5-3.7
7
7
オッズオン
43.5
3.6-5.6
といった感じで、1頭につき、枠番・馬番・馬名・単勝オッズ・複勝オッズ だけが残ります。
ここまでくれば後はどうにもなりますね。
先の、タグを取り除いた Regex.Replace() のような関数はC言語や他のプログラミング言語にもあるのかもしれません。
オッズ取得に、どのようなプログラミングをしたのかを説明してみましたが、プログラミングに熟達されている方なら、もっと上手にプログラミングを組めると思います。「大体こんな感じか」と参考になればと思います。
先のURLにある開催コードですが
https://www.nankankeiba.com/odds/201806112103010101.do
このレース部分を
FOR L=1TO12
R=L.Tostring(“00”)
NEXT
とすれば
/201806112103010101.do
/201806112103010201.do
/201806112103010301.do
・
・
・
/201806112103011201.do
と開催コードだけで12レースまで自動で取得してくれます。